MongoDB
MongoDB is a NoSQL database that is document-oriented, meaning it stores data in flexible, JSON-like documents. Unlike traditional relational databases, MongoDB does not rely on a fixed schema, allowing for dynamic and scalable data modeling.
- Is a Document-Oriented Data Model :
- Unlike SQL databases, MongoDB stores data in documents (similar to JSON objects), allowing each document to have its own unique structure.
- Uses B-Tree Indexing :
- Efficient Querying: MongoDB uses B-Tree indexing to speed up query operations.
- Multi-Key Indexes: MongoDB supports compound indexes that allow you to index multiple fields within a document, optimizing queries that filter by multiple criteria.
- ACID Transactions
- Uses Single Leader Replication:
- Primary-Secondary Architecture : The primary node accepts write operations, and these changes are then replicated to secondary nodes.
- High Availability: If the primary node fails, one of the secondary nodes is automatically elected as the new primary The Raft Consensus Algorithm - Leader Election.
- Read Preferences: While write operations are performed on the primary node, read operations can be distributed across secondary nodes to improve performance and availability.
- Supports sharding for Horizontal Scaling : Making it ideal for applications that need to handle large volumes of data and high traffic.
- Use Cases
- Content Management Systems: MongoDB’s flexible schema makes it ideal for managing unstructured data such as articles, blogs, and user-generated content.
- Real-Time Analytics: MongoDB’s support for high-throughput writes and its ability to handle large volumes of data make it suitable for real-time analytics applications.
Cassandra
Cassandra is a NoSQL database designed for handling large amounts of data across many commodity servers with no single point of failure. It uses a wide-column store model, where data is stored in rows and columns, and rows are grouped into tables.
Data Model
- Wide-Column Model: Data is organized into tables with rows and columns, similar to RDBMS, but it allows each row to have different columns.
- Primary Key:
- Partition Key (Cluster Key): Mandatory. Determines which node stores the data.
- Clustering Columns (Sort Key): Optional. Defines the sort order of rows within the same partition.
- Other columns are optional.
Note
How does Wide-Column Model look like?
Here is how data is represented in a key-value database:
Here is the same idea in a wide-column database:
We can look at wide-column stores as a 2-dimensional key-value store, where the first key is used as a row identifier and the second is used as a column identifier.



{kind=link}
Partitioning & Indexing
- Partitioning: Data is partitioned based on the partition key, ensuring that all reads and writes for a specific key go to the same partition, optimizing performance.
- Gossip Protocol ([[Conflict-Free Replicated Data Types - CRDTs#how-gossip-protocol-works-|How Gossip Protocol Works ??]]): Nodes share configuration and state information using the Gossip protocol to maintain cluster membership and partition ownership.
- Local Indexes: Supported, but Cassandra’s indexing is less flexible than RDBMSs, often leading to denormalization to optimize for read performance.
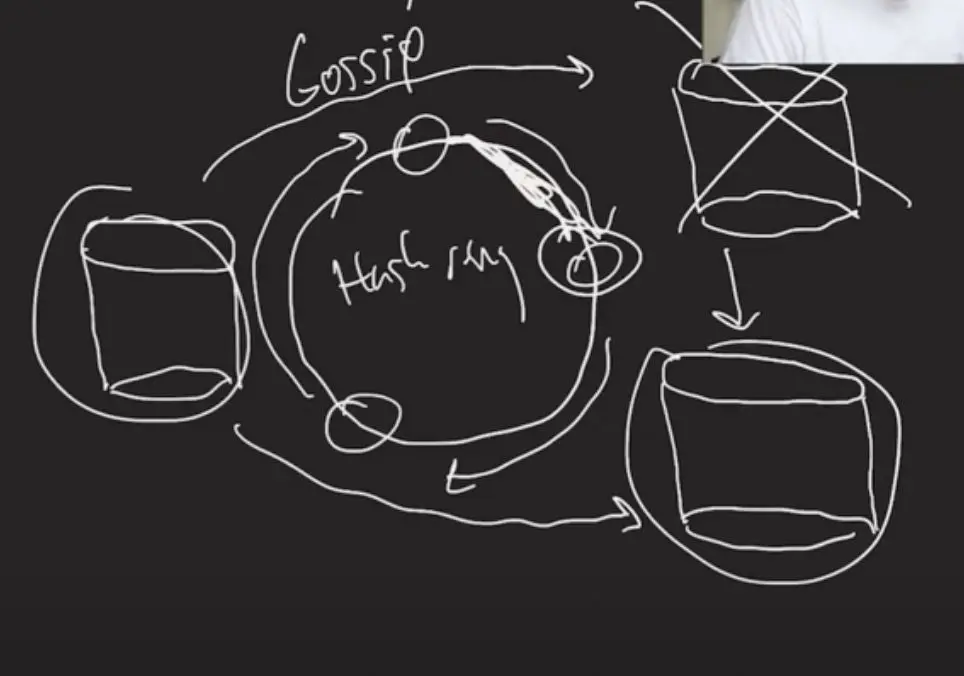
- All reads and writes should go to ONE Partition, very little support for distributed transactions.
Replication:
Configurable(if you don’t want Quorums you can configure to use single node for reads and write), Leaderless Replication → read repair, anti-entropy : Anti-Entropy.
Leaderless Replication: Cassandra uses a leaderless replication model, where any replica can accept write requests. Key points:
- Replication Factor: Configurable; determines how many nodes the data is replicated to.
- Quorums: You can configure read/write consistency levels, from a single node to a majority of replicas (quorum).
- Read Repair: Ensures consistency by repairing out-of-date replicas during read operations.
- Anti-Entropy: Periodically compares and synchronizes replicas to ensure consistency across the cluster. Read more here- Anti-Entropy.
Write Path & Conflict Resolution
Last Write Wins (LWW): Cassandra resolves write conflicts using the Last Write Wins strategy, which can lead to lost writes due to clock drift or network delays.
- LSM Trees (Log-Structured Merge Trees): In-memory data structure used to optimize writes.
- SSTables (Sorted String Tables): Persistent storage format on disk, optimized for write-heavy workloads.
Use Cases for Cassandra
- High-Volume Write Operations:
- Example: Log Aggregation Systems
- Explanation: Cassandra is highly optimized for write-heavy workloads due to its use of LSM Trees and SSTables. Systems that need to ingest large volumes of logs, metrics, or event data (e.g., application logs, server logs, or IoT sensor data) benefit from Cassandra’s ability to handle millions of writes per second across distributed nodes.
- Why Cassandra? Its architecture allows it to scale horizontally by adding more nodes, which increases the write throughput without a single point of failure. This makes it ideal for continuous data streams.
- Real-Time Analytics:
- Example: Recommendation Engines
- Explanation: Real-time analytics systems, such as those used by e-commerce platforms or media streaming services to provide personalized recommendations, can leverage Cassandra’s quick read/write operations. Data can be written rapidly as users interact with the platform, and it can be queried in near real-time to generate recommendations.
- Why Cassandra? The ability to store vast amounts of data with minimal latency in writes and reads, combined with its distributed nature, makes it ideal for building scalable, responsive analytics systems.
- Time-Series Data Storage:
- Example: Monitoring and Alerting Systems
- Explanation: Time-series data, like performance metrics from servers, application usage statistics, or IoT sensor readings, often require a database that can handle high write volumes and allow for querying by time intervals. Cassandra’s data model supports efficient querying by time, especially when the clustering key is based on a timestamp.
- Why Cassandra? It excels in managing time-series data due to its ability to store large datasets efficiently and retrieve time-based data quickly, making it perfect for monitoring and alerting systems that need to track and analyze time-dependent data.
- User Activity Tracking:
- Example: Social Media Platforms (e.g., Facebook Messages)
- Explanation: Social media platforms generate massive amounts of data, such as user posts, comments, likes, and messages, which need to be stored and accessed quickly. Cassandra’s model supports high write throughput, ensuring that user interactions are logged with minimal delay, and the partition key can be designed to efficiently query user-specific data.
- Why Cassandra? It’s particularly useful for applications where users generate continuous streams of data that need to be accessed in real-time. The wide-column model allows for efficient storage and retrieval of related user activity, making it ideal for messaging and activity feeds.
- Geospatial Data Applications:
- Example: Location-Based Services (LBS)
- Explanation: Geospatial applications that track and store large amounts of location data, such as those used in delivery tracking, ride-sharing, or mapping services, can benefit from Cassandra’s ability to handle large-scale distributed datasets. Cassandra can store geospatial data efficiently and retrieve it based on location-based queries.
- Why Cassandra? Its distributed nature allows for fast data retrieval across multiple regions, making it suitable for applications that require real-time location updates and fast access to large geospatial datasets.
Limitations:
- Distributed Transactions: Limited support; Cassandra does not support ACID transactions across multiple partitions, only within a single partition.
- Row-Level Locking: Cassandra offers only row-level locking, with no support for traditional ACID transactions.
Comparison with Alternatives
- Cassandra vs. MongoDB:
- MongoDB offers stronger data consistency and more flexible schemas, making it suitable for applications requiring data guarantees akin to SQL databases but with the flexibility of NoSQL.
- Cassandra is optimized for high throughput and scale at the cost of weaker consistency guarantees.
- Cassandra vs. Riak:
- Riak uses CRDTs (Conflict-free Replicated Data Types) to resolve conflicts more effectively, making it an alternative to Cassandra when stronger conflict resolution mechanisms are needed.
Conclusion
MongoDB: For when you need data guarantees of SQL Database but schema flexibility of NoSQL DB. Cassandra: Incredibly high single partition write throughput and read throughput. Very poor data guarantees.