{kind=link}
Introduction
Stream processing is basically real-time processing of a continuous data streams as they’re generated. Unlike, batch processing where data is collected over a period of time and then processed in chunks, stream processing involves ingestion, analysis and storage of data as it arrives, often within milli-seconds. Allows immediate insights and actions based on data being processed, it’s ideal for systems where there should be low latency and real-time decision making.
Stream processing systems often use distributed architectures to handle large volumes of data, allowing them to scale horizontally by adding more nodes. Popular frameworks for stream processing include Apache Kafka, Apache Flink, and Apache Storm.
Note
In general, a “stream” refers to data that is incrementally made available over time. The concept appears in many places: in the stdin and stdout of Unix, programming languages (lazy lists), filesystem APIs (such as Java’s FileInputStream), TCP connections, delivering audio and video over the internet, and so on.
Event/Message Broker or Message Queue
What if we want to be able to have many to many relationship b/w producers & consumer ??

A message broker is like a middleman (which is essentially a kind of database that is optimized for handling message streams) that helps different services or applications talk to each other. It runs as a server, with producers and consumers connecting to it as clients.
Instead of services directly sending messages to one another, they(producers) send them to the message broker (or message queue), which then other services(consumers) receive them by reading them from the broker.
It decouples the sender (producer) of a message from its receiver (consumer), enabling asynchronous communication and allowing services to interact without needing to know each other’s details or be directly connected.
Message brokers typically support various messaging patterns, including:
- Publish/Subscribe (Pub/Sub): Messages are published to a topic, and any service subscribed to that topic receives the messages.
- Point-to-Point: Messages are sent directly to a specific queue, and one consumer processes each message.
- Fan-out: A single message is sent to multiple queues or topics.
- Request/Reply: The producer sends a message and expects a response from the consumer.
Use Cases (Keeping Systems in Sync)
1. Metric/Log Time Grouping and Bucketing
In systems that generate continuous streams of metrics or logs, like monitoring tools, web servers, or application logs, it’s crucial to organize and analyze this data over time. Time Grouping and Bucketing are techniques used to manage and analyze this data by dividing it into manageable pieces.
Key Concepts
- Time Grouping : It involves aggregating or organizing events/data that occur within a specific time window. This allows you to analyze data in chunks, such as calculating averages, sums, or other metrics over fixed periods.
- Bucketing : It divides data into discrete chunks or “buckets” based on time intervals or other criteria. Each bucket contains data that falls within a particular range, making it easier to query, analyze, and manage.
Types of Time Windows Used in Grouping and Bucketing:
1. Tumbling Windows:
Non-Overlapping, Fixed-size windows. Each window contains data from a specific time interval, & once window closes, moves to next time interval without any overlap.
Example: If you have a 5-minute tumbling window, the first window might cover 0-5 minutes, the next 5-10 minutes, and so on.
Time: 0 1 2 3 4 5 6 7 8 9 10
|---|---|---|---|---|---|---|---|---|---|
Events: A B C D E F G H I J
Window 1 (0-5 min): |---|---|---|---|---| →→ Events: A, B, C, D, E
Window 2 (5-10 min): |---|---|---|---|---| →→ Events: F, G, H, I, JEach event belongs to one and only one window.
Tumbling windows are ideal for periodic reports or summary statistics.
2. Hopping Windows:
Similar to Tumbling Windows but with overlap.
Define : a window size and a hop size. Hop Size : Determines how often a new window starts.
Example: A 5-minute window with a 1-minute hop would look like this:
Time: 0 1 2 3 4 5 6 7 8 9 10
|---|---|---|---|---|---|---|---|---|---|
Events: A B C D E F G H I J
Window 1 (0-5 min): |---|---|---|---|---| →→ Events: A, B, C, D, E
Window 2 (1-6 min): |---|---|---|---|---| →→ Events: B, C, D, E, F
Window 3 (2-7 min): |---|---|---|---|---| →→ Events: C, D, E, F, GSince windows overlap, some events belong to multiple windows!
Hopping windows are useful for detecting patterns or trends that might span across multiple time intervals.
3. Sliding Windows:
Window where the window moves continuously over time, capturing events that occurred within the window size. Sliding windows - granular form of hopping windows with a hop size of one event (or one minimal time unit).
Example: A 5-minute sliding window would include events in the last 5 minutes, updating continuously as new events arrive.
Time: 0 1 2 3 4 5 6 7 8 9 10
|---|---|---|---|---|---|---|---|---|---|
Events: A B C D E F G H I J
Window (Last 5 mins): |---|---|---|---|---| →→ Events: D, E, F, G, H (sliding as new data arrives)Sliding windows are ideal for real-time monitoring and alerts where the most recent data is always relevant.
4. Session Windows:
Session windows group events based on activity within a session. Closes after a specified period of inactivity.
Example: If you define a session window with a 2-minute inactivity timeout, all events happening within 2 minutes of each other will be grouped together.
Time: 0 1 2 3 4 5 6 7 8 9 10
|---|---|---|---|---|---|---|---|---|---|
Events: A B C D E F
Session Window 1 (0-2 min): |---|---| →→ Events: A (0.5), B (1.2)
Session Window 2 (3-3 min): |---| →→ Event: C (3.1)
Session Window 3 (6-7 min): |---|---| →→ Events: D (6.4), E (7.0)
Session Window 4 (9-9 min): |---| →→ Event: F (9.3)- Session Window 1 (0-2 min): Captures events A (0.5) and B (1.2), then closes after 2 minutes of inactivity.
- Session Window 2 (3-3 min): Captures event C (3.1). Since no more events occur after C within the inactivity timeout, the session window closes immediately after event C.
- Session Window 3 (6-7 min): Captures events D (6.4) and E (7.0), then closes after 2 minutes of inactivity.
- Session Window 4 (9-9 min): Captures event F (9.3) and closes immediately since no other events follow.
2. Change Data Capture:
Change Data Capture (CDC) is a technique used to track and capture changes—like inserts, updates, and deletes—in a database. This captured data can then be replicated to other systems, such as search indexes, caches, or data warehouses, ensuring that these systems stay in sync with the original database (often referred to as the “system of record”).

Why CDC Matters?
Traditionally, databases treated their replication logs—records of all the changes made to the data—as an internal implementation detail, not meant for public use. This made it difficult to extract changes and replicate them to other systems. Without a documented way to access these logs, keeping external systems, like search indexes or data warehouses, in sync with the main database was challenging.
With the growing interest in CDC, databases are now providing ways to observe changes in real-time and make them available as a continuous stream of events. This allows for immediate replication to other systems, ensuring that they reflect the latest state of the database.
LinkedIn’s Databus, Facebook’s Wormhole, and Yahoo!’s Sherpa are examples of large-scale CDC implementations.
How CDC Works?
CDC works by monitoring the changes in a database and capturing them in the order they are written.
- Log-Based Capture:
- CDC often involves reading the database’s replication log (e.g., MySQL’s binlog, PostgreSQL’s write-ahead log). This log records every change made to the database.
- Trigger-Based Capture:
- Another method involves using database triggers. Triggers are pieces of code that run automatically when certain changes are made to a table.
- These triggers can record changes to a separate change-log table.
- Asynchronous Replication:
- In most CDC implementations, the system of record (the main database) does not wait for the changes to be applied to the consumers (like search indexes or data warehouses) before committing the transaction.
- This asynchronous nature prevents slow consumers from affecting the performance of the main database, though it can introduce issues like replication lag.
Use Cases of CDC:
- Data Replication: CDC keep a data warehouse or search index synchronized with an operational database.
- Event-Driven Architectures: : CDC can trigger other systems or micro-services in response to database changes. For instance, when a new order is placed in an e-commerce system, CDC can update inventory, send confirmation emails, and initiate shipping processes in real-time.
- Real-Time Analytics: CDC allows real-time data streaming to analytics platforms, enabling up-to-the-minute reporting and analysis. Crucial for scenarios like fraud detection.
- Data Synchronization: CDC ensures that different databases or systems that depend on the same data are kept in sync.
Challenges of CDC:
- Schema Changes - Handling schema changes (e.g., adding or removing columns) can be challenging, especially when parsing replication logs.
- Performance Overhead: - While log-based CDC is generally more robust, trigger-based CDC can introduce significant performance overhead and fragility on the DATABASE.
- Replication Lag: Since CDC is typically asynchronous, there can be a delay (lag) between when a change is made in the source database and when it is reflected in the target systems.
3. Event Sourcing:
Event Sourcing is an architectural pattern where the state of a system is derived from a series of immutable events, rather than storing the current state directly. In this pattern, every change to the system’s state is captured as an event, and these events are stored in an append-only log. The system’s current state can always be reconstructed by replaying these events in the order they were recorded.
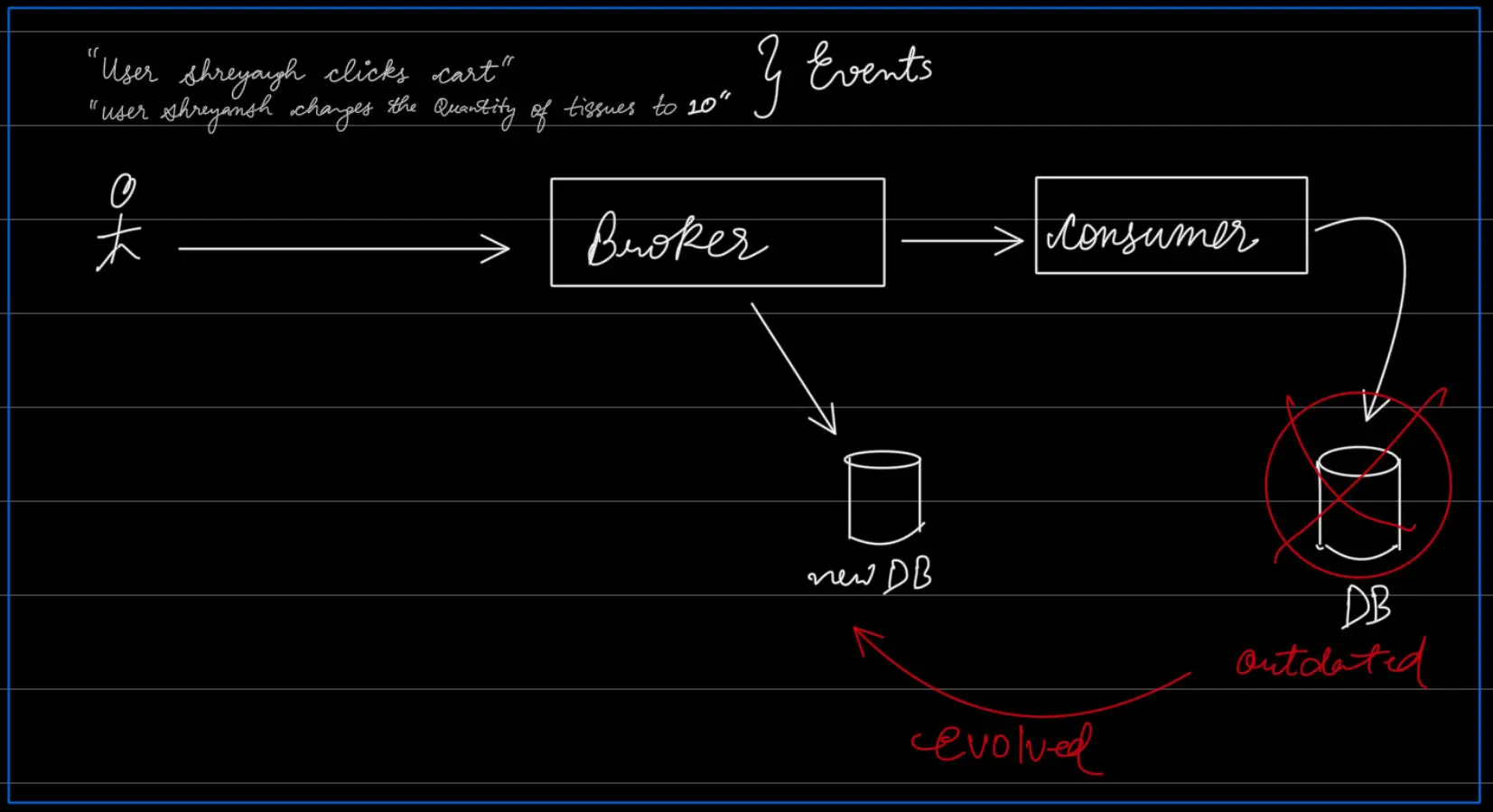 Those are events and not writes because these are database agnostic language.
Those are events and not writes because these are database agnostic language.
Database agnostic events allows us to build new types of derived data systems in the future! Assumption: Broker holds onto the events.
How Event Sourcing Works ?
- Events as the Source of Truth:
- In event sourcing, the events are the primary source of truth. Each event represents a fact about something that has occurred in the system (e.g., “OrderPlaced”, “PaymentProcessed”, “ItemShipped”).
- These events are immutable, meaning they cannot be changed once they are recorded. If something goes wrong, a compensating event is added to rectify the issue rather than modifying the existing event.
- Event Storage:
- Events are stored in an append-only log, often referred to as the event store. This log captures every event in the order it occurred, allowing the system to maintain a complete history of changes.
- The event log is append-only, ensuring that events are never deleted or modified. This immutability is critical for maintaining a reliable and auditable history of the system’s state.
- Rebuilding State:
- To determine the current state of the system, you simply replay all the events from the log in the order they occurred. This process is called event replay.
- The system doesn’t store the current state explicitly but derives it by applying each event to an initially empty state.
- Snapshots:
- In systems with a large number of events, replaying the entire event log might be inefficient. To optimize this, snapshots of the state can be taken periodically. A snapshot is a checkpoint that represents the state at a certain point in time.
- When reconstructing state, you start from the most recent snapshot and replay only the events that occurred after that snapshot.
Benefits of Event Sourcing Audit-ability, Flexibility in Business Logic(replay the events with the new logic to derive the updated state), Resilience, etc.
Real-World Examples:
- Banking Systems - Use Case: Transaction History.
- E-commerce Platforms - Use Case: Order Management (lifecycle of an order is captured as a series of events, “OrderPlaced”, “PaymentProcessed”, “OrderShipped”, and “OrderDelivered”).
- Social Media Platforms - Use Case: Activity Feeds (every user action—such as posting a status update, liking a post, or adding a friend—can be recorded as an event. These events are stored in an event log and can be replayed to build the user’s activity feed.)
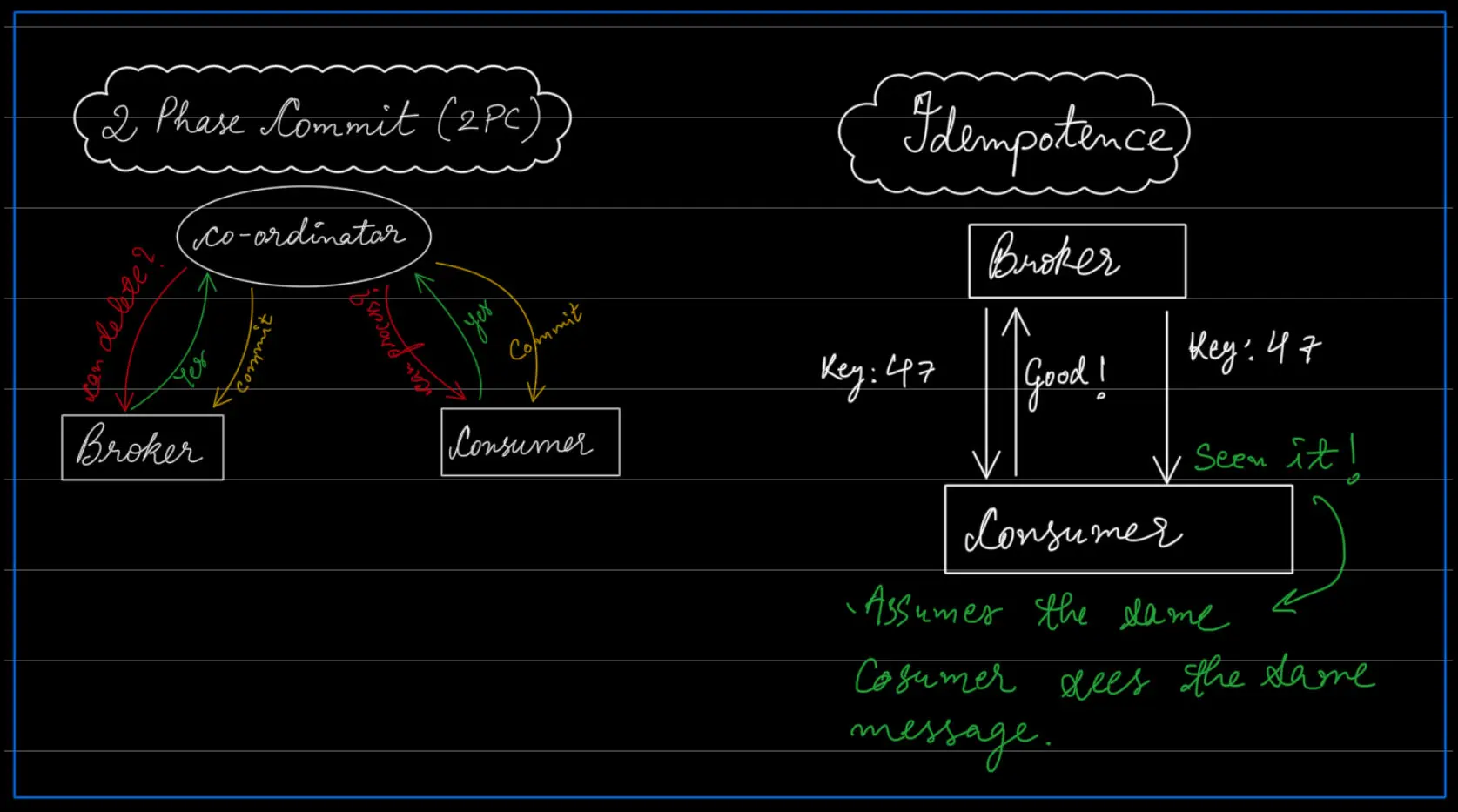
Exactly One Message/Event Processing
This means our event is processed “At least Once” and “Not more than once”.
- At Least Once:
- Fault Tolerant Brokers: To ensure that the event is processed at least once we need fault-tolerant brokers. This typically involves persisting messages to disk and replicating them across multiple nodes.
- Consumer Acknowledgments: In an “at least once” system, messages are re-delivered if no acknowledgment is received, ensuring that every message is processed at least once, but possibly more than once.
- No More Than Once Processing:
- Two-Phase Commit (bad - sloww): Involves a coordinator managing the transaction between the broker and the consumer. The coordinator ensures that a message is only committed and acknowledged once both the broker and the consumer agree that the message has been successfully processed.
- Idempotence (Nice): The consumer processes messages(with a key, for example: “key: 47”) in a way that if the same message is processed multiple times, the outcome remains the same. For example, if a message is processed that updates a database record to a specific value, applying this update multiple times will not change the final result.