{kind=link}
Introduction
Coordination services are just thin layer that’re built on distributed consensus algorithm like Raft (The Raft Consensus Algorithm - Leader Election). Basically can help us with all that configuration that we might need within our distributed backend. What types of configurations? IPs for servers and DBs, replication schema (what db is sending writes to which, who’s the leader, where are those DBs located, etc) & partitioning breakdown. Can’t mess this up!
ZooKeeper achieves strong consistency through a consensus algorithm called Zab (ZooKeeper Atomic Broadcast). Zab ensures that all updates to the ZooKeeper state are totally ordered, meaning that once a write has been acknowledged, it is guaranteed to be visible to all clients in the same order. This is crucial for maintaining consistency across all nodes in the ZooKeeper ensemble.
Recall: Consensus is sloww, but sometimes we need it! For example the above configurations.
A coordination service is a key-value store that allows us to store this data in a reliable way. example: Zookeeper, etcd
How reads work?
Built on top of distributed consensus layer like Raft.
- Can always read from leader (slow).
- If you want to read from multiple nodes, SYNC will keep reads linearizable (only needs to be done once, greater read throughput as a result).
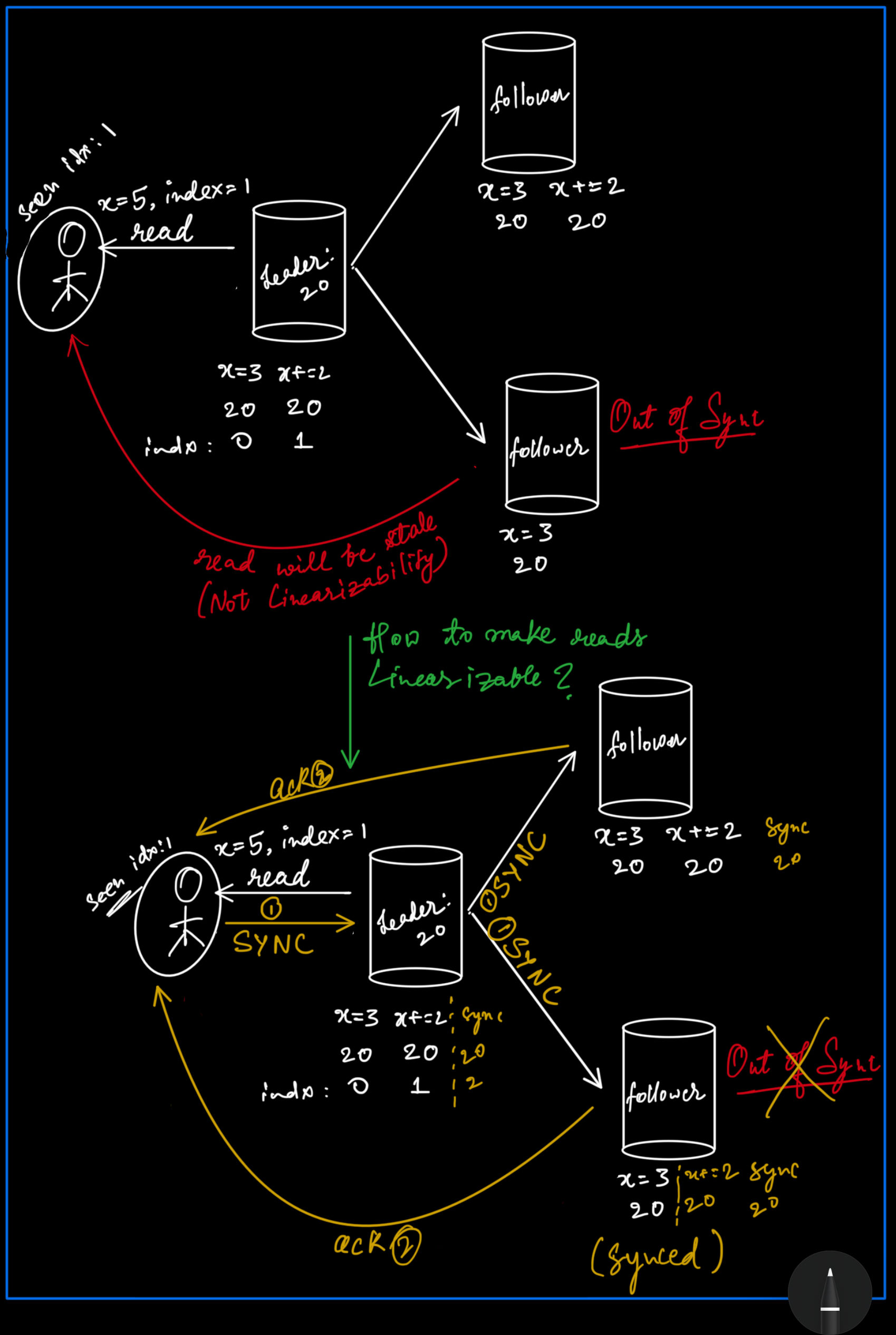
Linearizable Reads and the sync Keyword:
In ZooKeeper, the sync keyword is used to ensure linearizable reads, meaning that a read operation reflects the most recent write operation that was acknowledged by the leader.
However, the concern you’ve raised about the sync keyword and quorum reads highlights an important nuance in distributed systems:
- Quorum Reads: In a system like ZooKeeper, a read operation can be performed by contacting a majority (quorum) of the nodes. This can provide faster reads but doesn’t guarantee that the read is from the most up-to-date node, as the leader may have committed a write that has not yet been propagated to the followers.
- Using sync: The sync operation forces the follower to update itself by contacting the leader before proceeding with the read. This ensures that the read reflects the latest committed state. However, this doesn’t guarantee that the follower will stay up-to-date, as another write could be committed to the leader after the sync operation. If multiple users are writing to the leader, it’s possible that the follower may not immediately reflect subsequent writes.
The Role of Consensus
ZooKeeper’s consensus algorithm ensures that once a write is committed by the leader, it will eventually be propagated to all followers. However, there is always a brief window where a follower may lag behind. This is why ZooKeeper provides the sync operation—to mitigate this lag for read operations, ensuring that they reflect the most recent committed write.
So, while ZooKeeper does provide strong consistency, it’s essential to understand the nuances of how reads and writes are handled in a distributed environment. The trade-off between performance and consistency is a key consideration in designing systems that use ZooKeeper.
If you’re asking whether ZooKeeper provides strong consistency using consensus algorithms, the answer is yes, through the Zab protocol. However, the behavior of reads and the need for synchronization operations like sync are part of the design choices to manage the balance between consistency, availability, and performance.
Conclusion:
Too slow to be used for application data, only key pieces of configuration for your back-end needs to be correct. Built on top of consensus algorithms to maintain linearizability. It’s OKAY if reads are little bit out-dated but we’d never jump backwards in Time to some previous state and think that it is more up-to-date than our current state.