Introduction
As an alpha sigma Male myself, not a big fan of having multiple leaders. Clearly, such a setup is destined to fail and has many problems with it, as you’ll see in the following article.

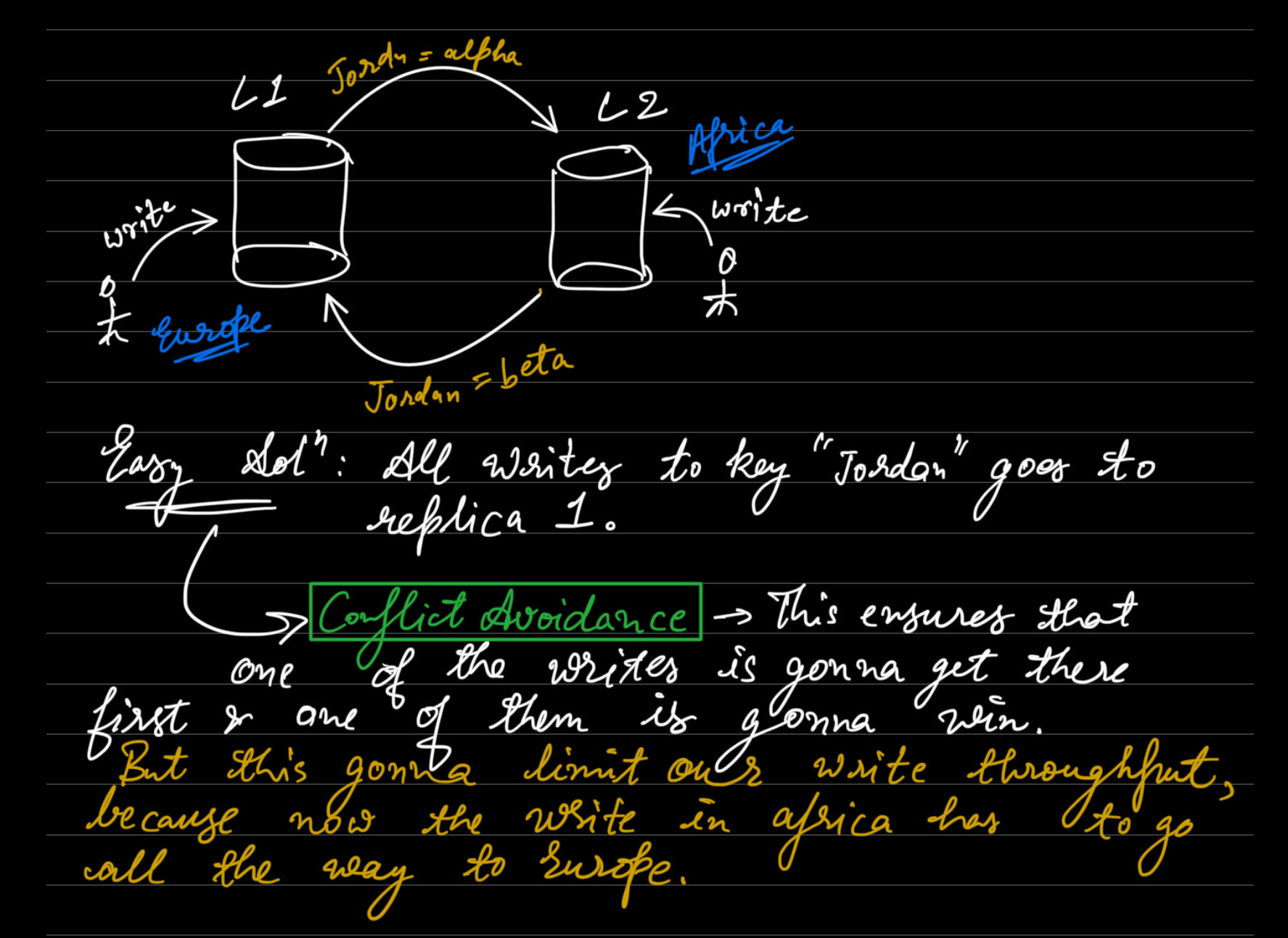
- Anyone can write to any Leaders and they can write anything and we can read from followers to which the writes will be propagated asynchronously.
- The guy in Europe doesn’t have to write all the way to Africa or APAC.
Configurations where Leaders can pass their writes from one to another.
Topologies:
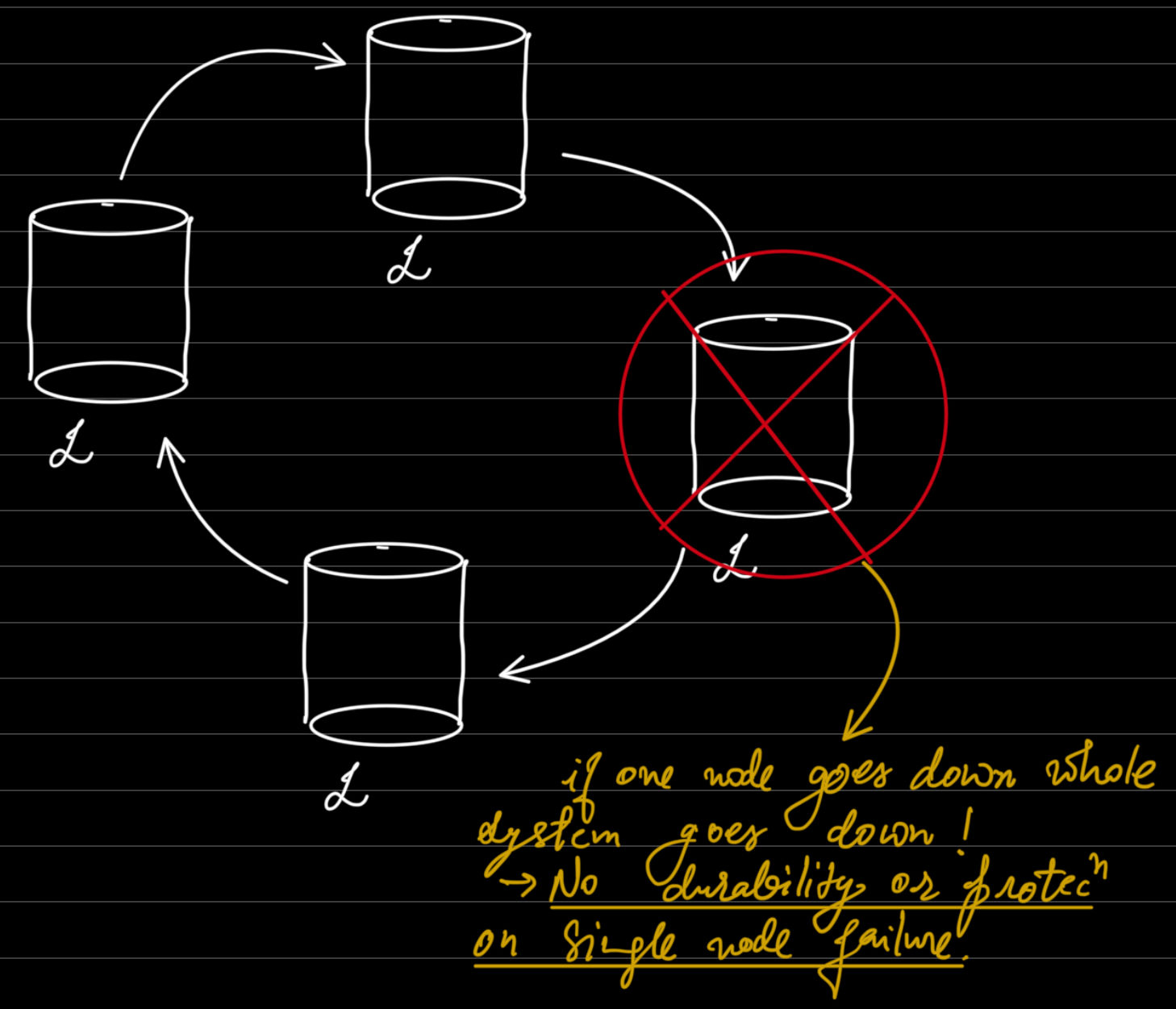
- Circle Topology:
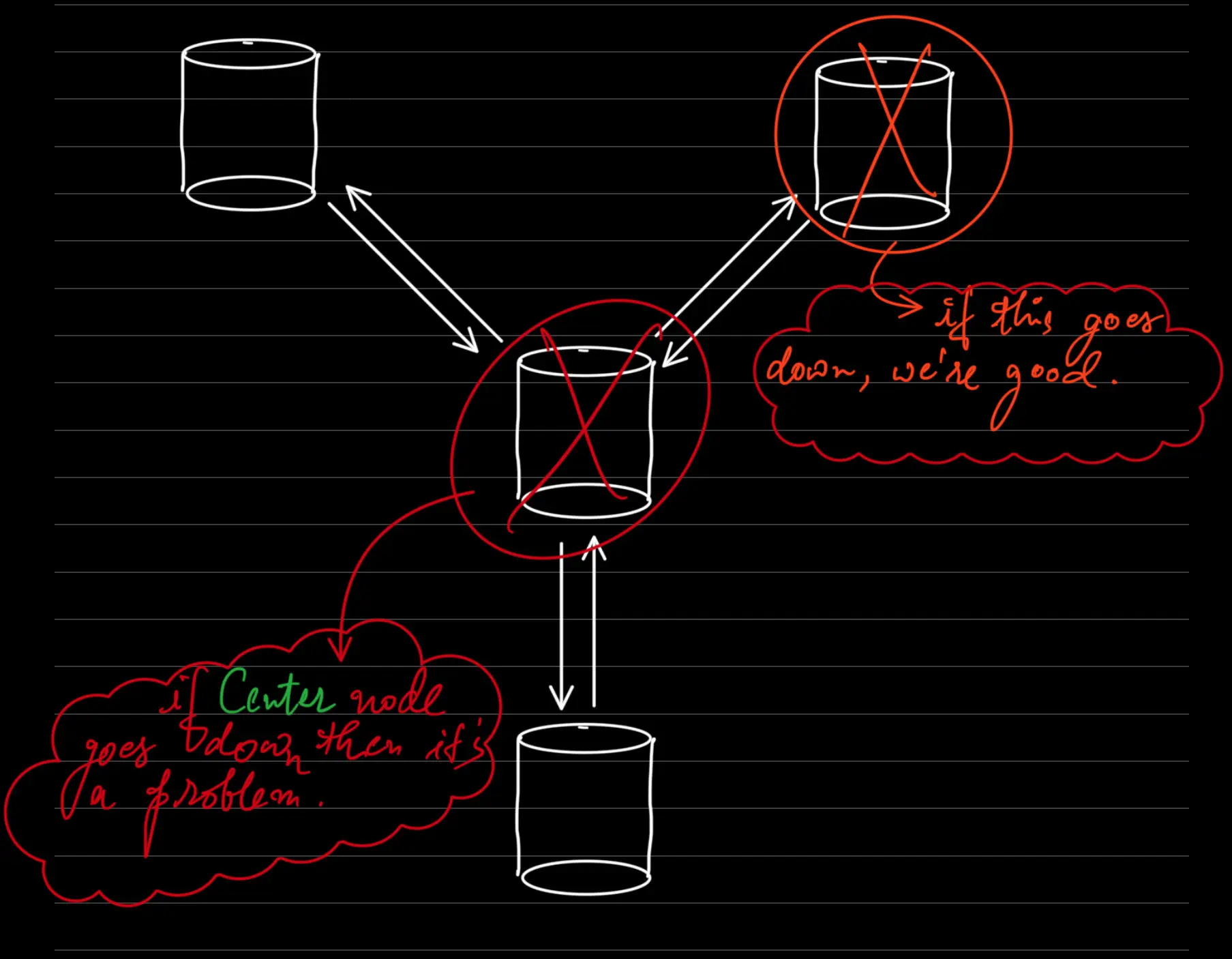
- Start topology
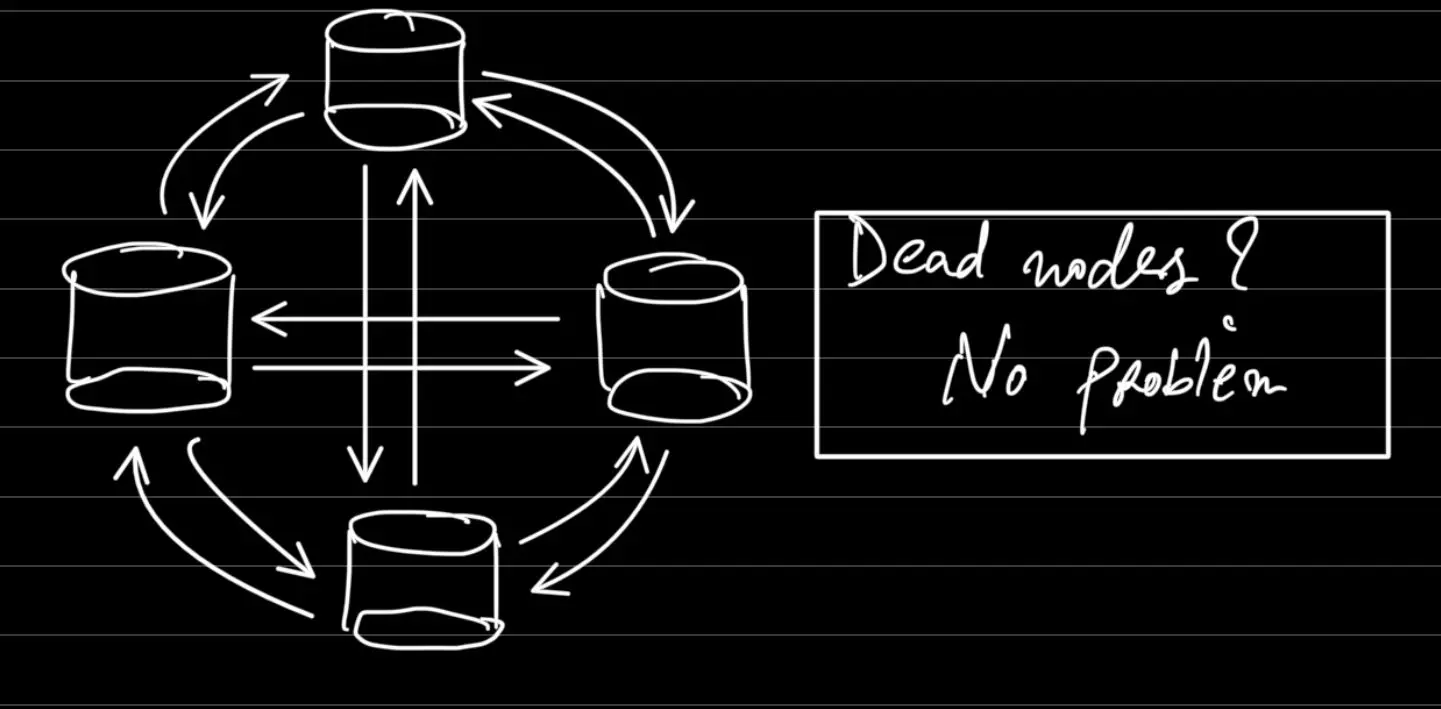
- All to All Topology
{kind=link}
Disadvantages of All-to-All Topology
-
Network Overhead:
- High network traffic due to each node needing to communicate with every other node.
- This can lead to significant bandwidth usage and increased latency, especially in large systems.
-
Complexity:
- Managing a large number of connections becomes complex and error-prone.
- More sophisticated conflict resolution mechanisms are needed to handle concurrent writes and ensure data consistency.
-
Scalability Issues:
- As the number of nodes increases, the number of connections grows quadratically (N*(N-1)/2).
- This limits the scalability of the system and can lead to performance bottlenecks.
-
Conflict Resolution:
- Increased likelihood of conflicts due to simultaneous writes on different nodes.
- Requires robust conflict resolution strategies (e.g., Last Write Wins, custom resolution logic) which can be difficult to implement effectively.
-
Data Consistency Challenges:
- Ensuring data consistency across all nodes is challenging due to the asynchronous nature of replication.
- Temporary inconsistencies can arise, making it difficult to provide strong consistency guarantees.
Modifying the Replication Log:
| Before (in Replication Log) | After (add this) |
|---|---|
| id: 5, key: Jordan, value: sexy | Seen by: 1, 3, 5 ⇒ (which replicas has seen this write? Don’t want to duplicate!!) |
| To keep track of this write as it goes to a specific node, we can add that in our replication log that this write was seen by that specific DB node. | |
| This will ensure that our systems are not sending the writes infinitely in all the directions if we know that this write has been seen by these many DB nodes. |
Write Conflicts: