{kind=link}
Introduction
If there are replicas, every write must be confirmed by nodes to be considered successful, and we must query at least nodes for each read. (In our example, .) As long as , we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date. Reads and writes that obey these r and w values are called quorum reads and writes. You can think of and as the minimum number of votes required for the read or write to be valid.
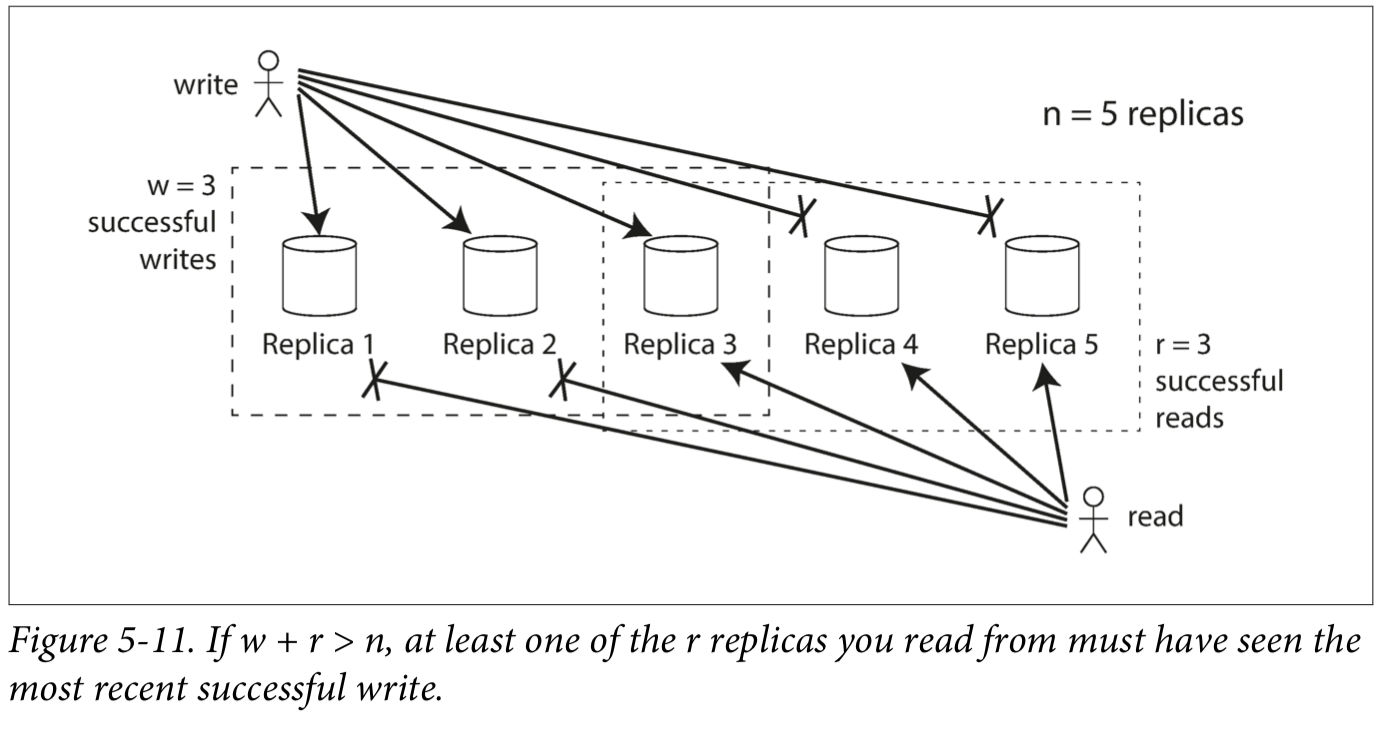
The quorum condition, , allows the system to tolerate unavailable nodes as follows: • If , we can still process writes if a node is unavailable. • If , we can still process reads if a node is unavailable. • With we can tolerate unavailable node. • With we can tolerate unavailable nodes. This case is illustrated in Figure 5-11. • Normally, reads and writes are always sent to all n replicas in parallel. The parameters and determine how many nodes we wait for ,, how many of the nodes need to report success before we consider the read or write to be successful.
Are quorums strongly consistent ??
: Will all users that perform a read at the exact same time get the same data? : No.
-
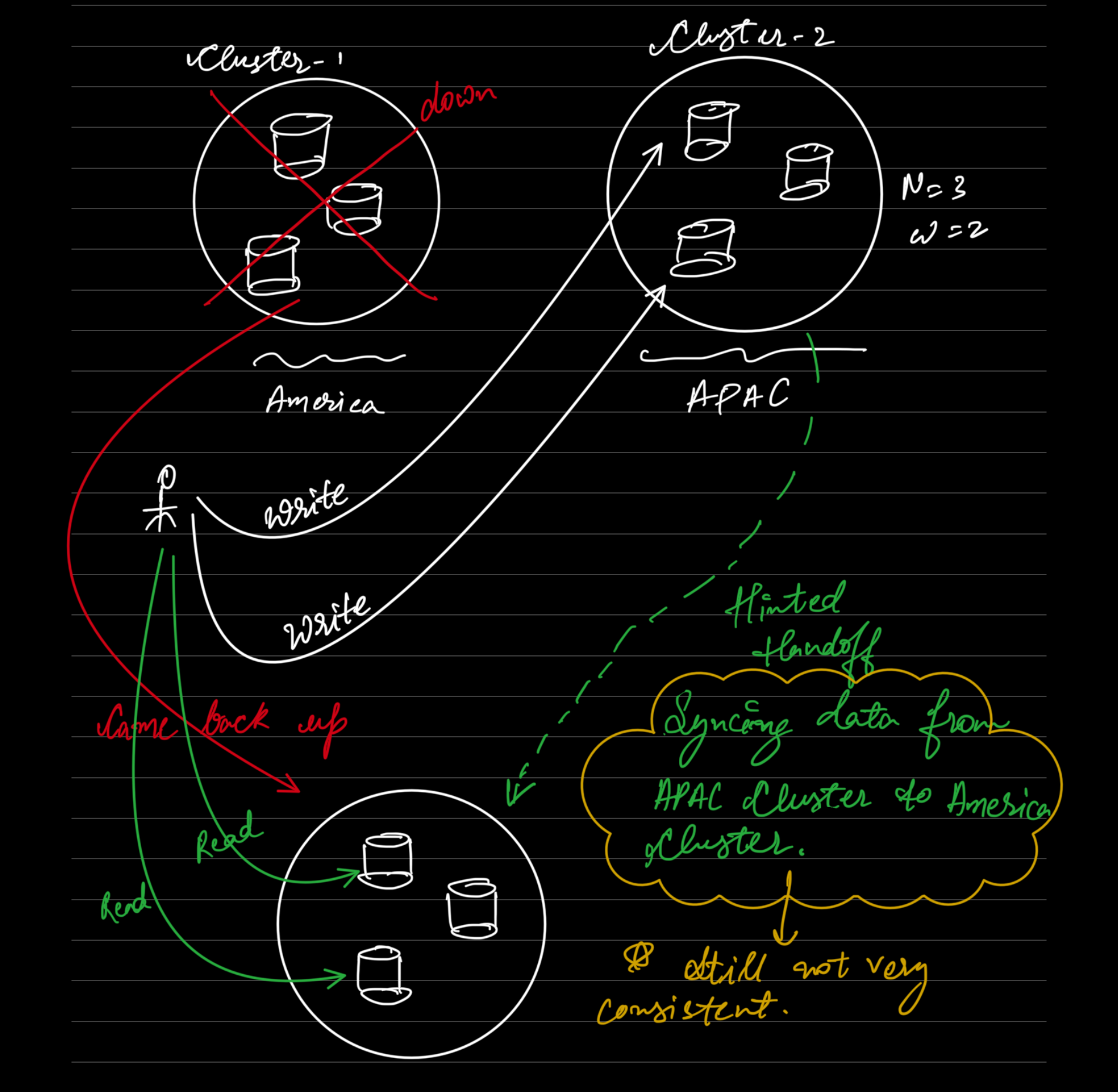
Sloppy Quorums and Hinted Handoff:
- When a sloppy quorum is used, write operations may be directed to nodes that are not part of the usual replica set. This can happen when some nodes are temporarily unavailable. As a result, subsequent read operations may access different nodes than those where the writes were recorded, leading to a lack of guaranteed overlap between the nodes handling reads and writes. This can cause inconsistencies as reads might not reflect the most recent writes.
-
Concurrent Writes:
- When two writes occur concurrently, it is unclear which one should be applied first. The safest approach is to merge the concurrent writes to avoid data loss, but this can introduce complexities in the application logic. If a last-write-wins approach based on timestamps is used, clock skew can lead to writes being overwritten incorrectly, resulting in lost updates and inconsistencies.
-
Concurrent Write and Read Operations (Race Conditions):
- If a write happens at the same time as a read, the write might only propagate to some replicas by the time the read operation occurs. Consequently, the read might return either the old value or the new value, leading to nondeterministic behavior and inconsistencies. This is a classic race condition scenario where the timing of operations leads to unpredictable results.
-
Partial Write Failures:
- If a write operation succeeds on some replicas but fails on others (, due to full disks), and the overall success count is fewer than the required replicas, the write is considered a failure.
- However, the replicas where the write succeeded will not roll back the change. This means that a subsequent read might return the value from the failed write, introducing inconsistency since the write was reported as unsuccessful.
-
Node Failures and Replica Restoration:
- If a node carrying a new value fails and its data is restored from a replica that has an older value, the number of replicas holding the new value might fall below the required quorum . This breaks the quorum condition, and subsequent reads may return outdated data, leading to inconsistencies.
-
Race Conditions in Coordination:
- In distributed systems, race conditions can arise not only between concurrent reads and writes but also in the coordination of operations among nodes. For instance, if two nodes independently decide to handle a write operation at nearly the same time, they might not be aware of each other’s actions, leading to conflicting states. Proper synchronization and coordination mechanisms are crucial to mitigate these race conditions.
Conclusion:
Quorums are great, but they’re not perfect! Leaderless databases setup can be good for certain applications, but if you want completely correct data don’t rely on them!